

تحلیل کواریانس در SPSS برای دانشجویان مدیریت، علوم اجتماعی و رشته های مشابه
در شرایطی، ممکن است که محقق در صدد بررسی تفاوت وضعیت دو گروه کنترل و ازمایش قبل و بعد از اجرا یا پیاده سازی یک متغیر باشد. در این شرایط استفاده از تحلیل کواریانس پیشنهاد می شود. برای روشن تر شدن موضوع اجازه دهید مثالی بزنیم. در یک پژوهش، محقق در صدد بررسی نقش زیباسازی محیط بر احساس خوشایندی کارکنان در شرکت X است. بدین منظور وی کارکنان شرکت را به دو گروه کنترل و ازمایش به تعداد مساوی تقسیم می کند، و در طی دو مرحله پرسشنامه هایی بین آنها توزیع می کند. مرحله اول که قبل از زیباسازی محیط سازمان است، که از آن به عنوان پیش آزمون یاد می شود و در مرحله دوم که پس از اجرای طرح زیبا سازی است که از آن به عنوان پس آزمون یاد می شود.
برای این منظور محقق می تواند فرضیه ها را به شکل های مختلفی طراحی نماید برای مثال
زیباسازی محیط شرکت باعث افزایش احساس خشنودی کارکنان می شود.
زیباسازی محیط شرکت تاثیری در افزایش احساس خشنودی کارکنان شرکت ندارد.
احساس خشنودی کارکنان در گروه کنترل و آزمایش در نتیجه زیبا سازی محیط شرکت، به صورت یکسان یا مشابه است.
احساس خشنودی کارکنان در گروه کنترل و آزمایش در نتیجه زیبا سازی محیط شرکت با یکدیگر متفاوت است.
باید در نظر داشت که طراحی فرضیه ها به شکل های مختلفی ممکن است صورت بگیرد، اما باید به ازمون پذیر بودن فرضیه ها نیز توجه جدی شود.
برای طراحی فرضیه ها در ازمون های کواریانس می توان از جمله بندی های متفاوتی استفاده کرد، که در ادامه به آنها اشاره می شود.
همانطور که قبلاً اشاره شده، برای ازمون کواریانس یک طرفه باید موراد زیر برقرار باشد
متغیر مستقل: یک متغیر مستقل که در محیط آزمایش به اجرا گذاشته شده است، برای مثال، آموزش مدیریت بر استرس
یک متغیر وابسته: متغیری که محقق در صدد ارزیابی آن هست که متغیر مستقل بر ان تاثیری دارد یا نه؟
توزیع پرسشنامه در دو مقطع زمانی متفاوت: که اصولا از آن به عنوان پیش آزمون و پس آزمون یاد می شود.
گروه بندی تعداد نمونه: در هر وضعیت پس آزمون و پیش آزمون دو گروه کنترل و آزمایش داریم.
حال با توجه به موارد فوق، به طراحی فرضیه های پژوهش می پردازیم:
حالت اول: مدیریت اموزش استرس(متغیر مستقل) بر کاهش ترس (متغیر وابسته) بیماران (نمونه پژوهش که به صورت کلی ذکر شده است) تاثیر گذاراست.
در بیشتر تحقیقات روانشناسی، دانشجویان اصولا طراحی فرضیه های خود را به شکل فوق انجام میدهند. اما مسئله ای که وجود دارد، در این فرضیه، به گروه بندی نمونه آماری توجه نشده است. اما اهمیت مطرح شدن گروه در فرضیه به چه دلیل است؟
اول: در انتخاب نوع آزمون تاثیر گذار است. برای مثال در فرضیه بالا محقق در صدد بررسی تاثیر مدیریت اموزش بر استرس بیماران است، با توجه به این که اشاره ای به گروه در این فرضیه نشده است، بنابراین در صورت نرمال بودن داده ها، می توان از آزمون تی تک نمونه و در صورت غیر نرمال بودن از آزمون دو جمله ای استفاده کرد.
دوم: در صورتی که به دو گروه اشاره شود، در این صورت می توان از ازمون مقایسه زوجی استفاده کرد. اما باید در نظر داشت که، گروه نمونه آماری به عنوان متغیر مستقل در نظر گرفته نشود.
سوم: در صورتی که محقق بدون توجه به جمله بندی فرضیه خود، از آزمون کواریانس یک طرفه اشاره کند، در تحلیل نتایج پژوهش خود از این بابت که متغیر مستقل بر متغیر وابسته در گروه کنترل و ازمایش در پیش آزمون و پس آزمون تاثیر دارد، مطمئن نخواهد بود.
در حالتی ممکن هست که محقق فرضیه های خود را این گونه طراحی کرده باشد،
آموزش مدیریت استرس باعث کاهش ترس در بین بیماران گروه های کنترل و آزمایش می شود.
در این فرضیه، بیماران به دو گروه تقسیم شده اند، بنابراین باید از آزمونی استفاده شود که وضعیت تفاوت میانگین ها در دو گروه را نشان دهد. اما مشکلی که در این فرضیه وجود دارد، ماهیت گروه کنترل و آزمایش است. در واقع در این فرضیه مشخص نشده که وضعیت زمانی برای هر دو گروه به چه شکلی هست و همین مسئله باعث انتخاب روش نامناسب برای تحلیل داده ها می شود. نکته دیگری که باید به آن توجه شود، آن هست که، زمانی که در صدد بررسی تفاوت ها بین دو یا چند گروه هستیم، بهتر است، فرضیه را به گونه ای طراحی کنیم که میانگین یا میانه (برای داده های ناپارامتریک) بین آن گروه ها از لحاظ تفاوت یا عدم تفاوت بررسی شود. بر همین اساس فرضیه فوق را می توان به شکل زیر تغییر داد
تفاوت معناداری بین ترس بیماران در گروه کنترل و آزمایش در حالت پس آزمون و پیش آزمون وجود دارد.
یا
برنامه آموزش مدیریت باعث ایجات تفاوت معنادار بین ترس بیماران گروه کنترل و آزمایش در حالت پس آزمون و پیش آزمون می شود.
باید در نظر داشت که در فرضیه هایی که تفاوت معنادار بررسی می شود، باید ادعای H1 پذیرفته شود، به عبارتی، مقدار سطح معناداری ها کمتر از سطح خطای پژوهش شود.
بعد از گردآوری داده ها و اطمینان از پایایی و نرمال بودن داده ها برای گروه کنترل و آزمایش در وضعیت پیش و پس آزمون، محقق می تواند داده های متغیرها را در آزمون کواریانس بررسی نماید. برای این کار باید مطابق شکل از مسیر Analyze به مسیر general Linear Model مراجعه شود، که در نتیجه این عمل، کادری با چهار آزمون برای محقق نشان داده می شود. برای آزمون کواریانس یک متغیره باید از مسیر Univariate و برای کواریانس چند متغیره باید از Multivariate استفاده کرد. این که از کدام یک از روش ها برای تحلیل فرضیه استفاده کرد، بستگی به تعداد متغیرهای وابسته پژوهش دارد. برای مثال به فرضیه زیر دقت فرمائید
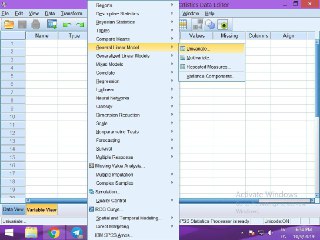
تفاوت معناداری بین ترس بیماران در گروه کنترل و آزمایش در حالت پس آزمون و پیش آزمون وجود دارد.
در این فرضیه، ترس بیماران به عنوان متغیر مستقل ارائه شده است. با توجه به این که تنها یک متغیر در این فرضیه ارائه شده است می توان از مسیر Univariate برای تحلیل فرضیه ها استفاده کرد. اما در صورتی که فرضیه فوق به شکل زیر تغییر کند:
تفاوت معناداری بین ترس، افسردگی و استرس بیماران در گروه کنترل و آزمایش در حالت پس آزمون و پیش آزمون وجود دارد.
با توجه به این که در فرضیه فوق، ترس، افسردگی و استرس بیماران به عنوان متغیرهای مستقل پژوهش ارائه شده اند، در این صورت باید از مسیر Multivariate برای آزمون فرضیه ها استفاده کرد.
با توجه به آنچه گفته شد مشاوره انجام پایان نامه به بهترین شکل ممکن لازمه یک تحقیق موفق و با اصالت جمع آوری داده، واکاوی و تجزیه و تحلیل آماری است که نیازمند بهره مندی و کسب مشاوره از متخصصین علوم آمار و آشنا به مفاهیم، فرضیات و آزمونهاست. در موسسه علم گستر در زمینه انجام مشاوره آماری، انجام مقاله و مشاوره انجام پایان نامه به شما دانشجویان گرامی خدمات مختلفی در نظر گرفته شده است.